 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-to-Music Recommendation using Temporal Alignment of Segments
Jun 12, 2023We study cross-modal recommendation of music tracks to be used as soundtracks for videos. This problem is known as the music supervision task. We build on a self-supervised system that learns a content association between music and video. In addition to the adequacy of content, adequacy of structure is crucial in music supervision to obtain relevant recommendations. We propose a novel approach to significantly improve the system's performance using structure-aware recommendation. The core idea is to consider not only the full audio-video clips, but rather shorter segments for training and inference. We find that using semantic segments and ranking the tracks according to sequence alignment costs significantly improves the results. We investigate the impact of different ranking metrics and segmentation methods.
Learning to rank music tracks using triplet loss
May 18, 2020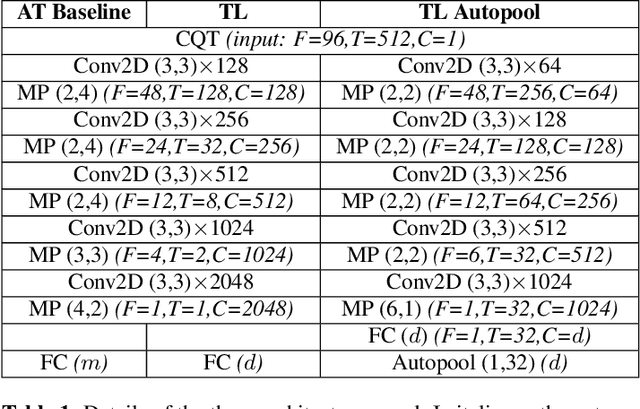
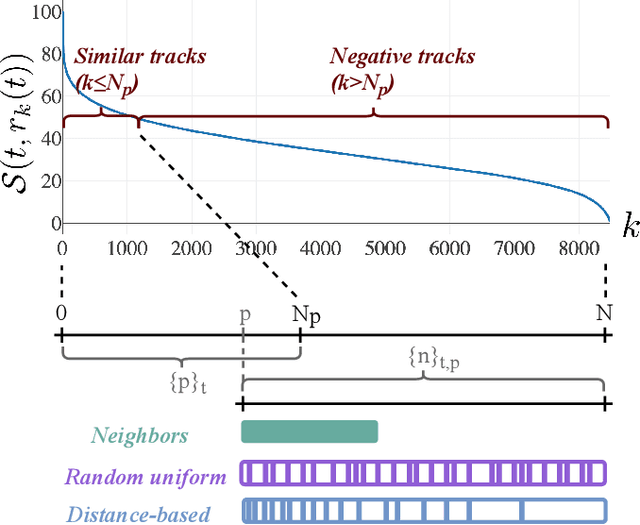
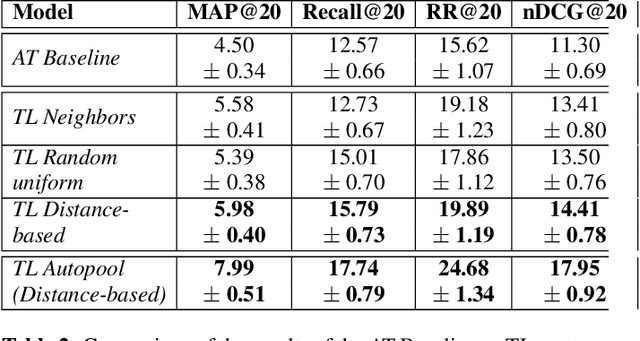
Most music streaming services rely on automatic recommendation algorithms to exploit their large music catalogs. These algorithms aim at retrieving a ranked list of music tracks based on their similarity with a target music track. In this work, we propose a method for direct recommendation based on the audio content without explicitly tagging the music tracks. To that aim, we propose several strategies to perform triplet mining from ranked lists. We train a Convolutional Neural Network to learn the similarity via triplet loss. These different strategies are compared and validated on a large-scale experiment against an auto-tagging based approach. The results obtained highlight the efficiency of our system, especially when associated with an Auto-pooling layer.